Movie Recommender System

Overview
This is a simple movie recommender system that uses movie genres to measure movie similarity. The model was then deployed into a flask web application that gives users real-time access to check movie recommendations.
App Features
- The app returns basic information of five (5) most similar movies to the movie searched for
- It has an autocomplete feature on the search bar to save you from typing long movie titles.
- On the homepage, you get to see a list of movies trending now
The web app was built with Flask and a sprinkle of JavaScript. The model uses the cosine similarity measure to measure movie similarity using genres.
Movies with similar genres will have higher similarity values. You can replicate this similarity measure on as much text data as is available.
Links
Webapp (This looks good only on desktop, honestly)
I’ll be going through all the steps I followed to build the Movie Recommender;
- Data Collection and Preprocessing
- Algorithm Setup
- Building the Webapp (Frontend and Backend)
- Deployment
Data Collection and Preprocessing
The process of choosing the data to use was a little chaotic cause I kept going back and forth on what I wanted. I finally used the TMDB 5000 Movie Dataset. I cleaned the dataset and kept the title, genres information for each movie.
Data Cleaning
The TMDB 5000 had 4803 rows and 20 columns, but after cleaning the data and removing missing values, I was left with 4775 rows and 2 columns.

The genre information for each movie was stored in a list of dictionaries containing the genre-ids and genre-categories, in this form, the genre information is unusable, so it needed to be cleaned.
I used Regex, Abstract Syntax Tree and string methods to clean the data, the complete data cleaning code is in the Data processing.ipynb file.


Data Collection
The app also collects data continuously to provide the best user experience. The trending movies are pulled from the TMDB API once a week, and the app displays them at random on every load, and for every recommendation request sent by the user, the app pulls movie information from the API.
For the trending movies; I used TMDB’s get popular movies endpoint, this returns information about the movies that are currently popular.
#get popular movies from TMDB
import requests#set endpoint parameters
params = ( ('api_key', api_key),
('language', 'en-US'),
('page', '1'),)#make API call
requests.get('https://api.themoviedb.org/3/movie/popular',
params=params)
For the recommended movies; the app uses cosine similarity to measure the similarity of movies to the user’s movie, gets the title of the 5 most similar movies and then uses the tmdbsimple wrapper to get the information of each movie and display it on the frontend.
import tmdbsimple as tmdb
import functions#calculating cosine similarity using the custome function from functions.py
cosine_similarity_df = functions.cosine_similarities(movies,
'genres')#get the titles of the 5 most similar movies using custom function from functions.py
names = functions.get_recommendations(cosine_similarity_df,
movie_title)#API CALL USING tmdbsimple TO GET INFORMATION ON RECOMMENDED MOVIES
search = tmdb.Search()
for n in names:
g = ''
response = search.movie(query=n)
response = response['results'][0] fetched_overviews.append(response['overview'])
fetched_imgs.append(img_base_url + response['poster_path'])
fetched_ratings.append(response['vote_average'])
fetched_dates.append(response['release_date'].split('-')[0])
genre_ids = response['genre_ids']
for k in genre_ids:
if k in genre_key:
g += genre_key[k] +', '
fetched_genres.append(g)return(render_template('positive.html', movie_title = movie_title, recommended_movies = names,posters = fetched_imgs, year = fetched_dates,ratings = fetched_ratings, plots = fetched_overviews,genres = fetched_genres))
Algorithm Setup
Cosine similarity is a measure of distance between two non zero vectors of an inner product space. If this distance is less, there will be a high degree of similarity, but when the distance is large, there will be a low degree of similarity.
The cosine similarity is advantageous over other similarity measures because even if the two items are far apart by the Euclidean distance (due to the size of the document), chances are they may still be oriented closer together. The smaller the angle, the higher the cosine similarity.
The mathematics behind cosine similarity
Calculating Movie Similarity
The text data (movie genres) needs to be converted into a meaningful representation of numbers that can be fed into machine algorithms. There are several ways to vectorize text data for machine learning. I used the TfidfVectorizer, which uses the weight of words in the document to create features.
from sklearn.feature_extraction.text import TfidfVectorizer#instantiate the vectorizer
vectorizer = TfidfVectorizer(max_df=0.2, min_df=0.1)#convert the movie genres into a matrix
vectorized_data = vectorizer.fit_transform(movies['genres'])#add movie titles to the vectorized data
tfidf_df = pd.DataFrame(vectorized_data.toarray(), columns=vectorizer.get_feature_names())

The result up here has converted the text information into numbers, the first row shows that Furious 7 is an action movie, it is not an adventure or animation or comedy movie and so on…
The TF-IDF matrix is then fed into the cosine similarity algorithm to calculate movie similarity.
from sklearn.metrics.pairwise import cosine_similarity# Create the array of cosine similarity values
cosine_similarity_array = cosine_similarity(tfidf_df)# Wrap the array in a pandas DataFrame
cosine_similarity_df = pd.DataFrame(cosine_similarity_array, index=tfidf_df.index, columns=tfidf_df.index)

The cosine similarity now uses the values from the TF-IDF matrix to see how similar movies are to themselves.
The data frame shows the cosine similarity of movies. The first row shows that Furious 7 is perfectly similar to itself and not at all similar to all the other movies appearing in this frame, but on row 2, column 11 shows that X-Men: Apocalypse is very similar to All Superheroes Must Die and there we have a recommendation. I created a custom function ‘cosine_similarities’ to do the vectorization and cosine similarity processes easily.
I wrote a python function to get the 5 most similar movies to the requested movie.
def get_recommendations(cosine_similarity_df, title):
# Find the values for the movie entered by the user
cosine_similarity_series = cosine_similarity_df.loc[title] # Sort the cosine similarities highest to lowest
ordered_similarities =
cosine_similarity_series.sort_values(ascending=False) #select the second:sixth highest values (the first value is the
movie itself)
recommendations = list(ordered_similarities[1:6].index) return recommendations
Building the Web App
This bit was very exciting (…well the frontend).

The first thing you’ll see on the index page is an input box where the user can insert the movie name (I incorporated an autocomplete / suggestion feature just to make the search easier for users using JavaScript). After submission, the title is sent to the backend where the cosine similarity is calculated and compared with all the other movies in the dataset and the recommended movies are rendered through the flask app into the positive.html page where we’ll see the information for the five (5) most similar movies to our search term.
# backend
# rendering recommended movies pulled by Flask from TMDB to the index.htmlreturn(render_template('positive.html', movie_title = movie_title, recommended_movies = names, posters = fetched_imgs, year = fetched_dates, ratings = fetched_ratings, plots = fetched_overviews, genres = fetched_genres))# frontend
# using jinja template to accept the data from flask
<div class="card">
<div class="poster-container">
<img class="poster" src="{{ posters[0] }}" alt="recommendation1"
/>
</div>
<h3 class="title">{{ recommended_movies[0] }}</h3>
<div class="rating">
<h5 class="star"><i class="fas fa-star"></i>{{ ratings[0]}}</h5>
<h5 class="year">{{ year[0] }}</h5>
</div>
<p>{{ genres[3] }}</p>
</div>
I added something extra to the homepage — trending movies, this data is pulled from the TMDB API in real-time once every week.
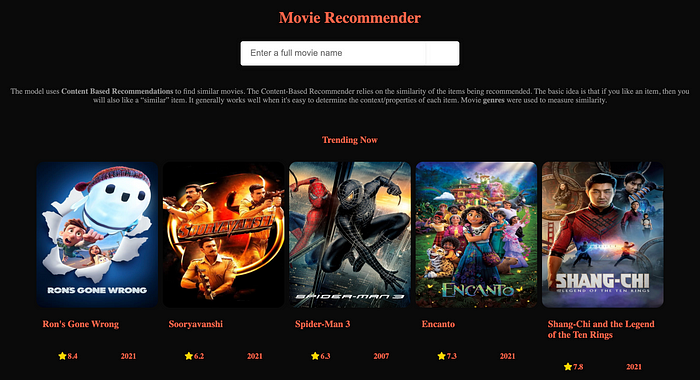
The Backend
The app.py file is the main code file, and all functions are in the functions.py file.
All libraries and modules were imported and Flask was initialized. I also accessed my TMDB API key from the Heroku config var.
The first thing that happens in the backend is the pulling of popular movies from TMDB.
Once a user enters the movie they would like to get recommendations for — If the movie searched for is already present in the dataset, the algorithm automatically starts looking for similar movies and displays them on the frontend. The rendering of recommended movies follows the same pattern as the rendering of popular movies shown earlier.
Deployment
I deployed my app to Heroku by following the following steps;
I created a Heroku account and then went back to my terminal and ran the following commands;
#add all changes the staging area
git add . git commit -m 'commit message'#login to heroku (this command opens up login page on a browser)
heroku login#create an app on heroku
heroku create#rename app (optional)
heroku rename newname#push app to heroku
git push heroku main
The flask app was now on Heroku, but I could not use it for recommendation yet because I had not provided the TMDB API key. The API key is a personal token that should not be included in the source code for safety reasons, it should be saved as an environmental variable. I did this by adding it to the config var on Heroku.

After adding the API key as an environmental variable, the app needs to be able to access it. I added this line of code to my app.py to access my TMDB API key.
api_key = os.environ['api_key']
This movie recommender system is very simple and lightweight because of computing power. Netflix, Disney, Spotify use more sophisticated and comprehensive features to provide more granular recommendations, but they all use the same idea as the model used here.
Take the app for a spin, and take a look at the source code.
Thank you for reading.
